Jak uruchomić lokalnego chatbota AI na karcie graficznej AMD Radeon lub procesorze Ryzen? Poradnik
Chcesz porozmawiać z AI, która działa na karcie Radeon lub procesorze Ryzen w twoim komputerze? Trenowanie lokalnych modeli LLM jest dostępne na sprzęcie AMD i potrafi wykorzystać zarówno NPU w procesorach, jak i możliwości kart graficznych.

Chatboty AI działające w chmurze mają dwie poważne wady. Przede wszystkim, karmimy je danymi, które mogą być poufne lub wręcz tajne, a potem nie wiadomo, kto i kiedy je wykorzysta. No i oczywiście każda awaria takiej usługi, czy po prostu internetu, odcina nas od pracy.
Rozwiązaniem są modele językowe działające lokalnie i wykorzystujące do tego moc kart graficznych, czy też dedykowanych koprocesorów (NPU - Neural Processing Unit) do przyśpieszania obliczeń związanych ze sztuczną inteligencją. Dobrym przykładem takiego oprogramowania jest NVIDIA ChatRTX (dawniej NVIDIA Chat with RTX) wykorzystujący moc kart GeForce.
O ile NVIDIA zdążyła wypuścić już dedykowaną do tego typu zadań aplikację, to w przypadku sprzętu AMD trzeba się posiłkować takimi narzędziami jak LM Studio - czyli oprogramowaniem do eksperymentowania z lokalnymi Dużymi Modelami Językowymi (LLM). Jeśli chcemy wykorzystać do obliczeń karty AMD, musimy znaleźć modele, które wspierają rozwiązanie ROCm (upraszczając, jest to taki odpowiednik NVIDIA CUDA dla kart Radeon).
Lokalna AI na karcie graficznej AMD Radeon lub procesorze Ryzen z NPU
Na ten moment (ROCm w wersji 6.02) w wersji na Windows (10 i 11) w pełni wspiera karty graficzne:
- AMD Radeon Pro W7900,
- AMD Radeon Pro W7800,
- AMD Radeon Pro W6800,
- AMD Radeon RX 7900 XTX,
- AMD Radeon RX 7900 XT,
- AMD Radeon RX 7600,
- AMD Radeon RX 6950 XT,
- AMD Radeon RX 6900 XT,
- AMD Radeon RX 6800 XT,
- AMD Radeon RX 6800.
Natomiast częściowo (bez wsparcia HIP SDK) modele:
- AMD Radeon Pro W6600,
- AMD Radeon RX 6750,
- AMD Radeon RX 6700 XT,
- AMD Radeon RX 6700,
- AMD Radeon RX 6650 XT,
- AMD Radeon RX 6600 XT
- AMD Radeon RX 6600.
W przypadku Linuksa są to modele AMD Radeon PRO W7900, AMD Radeon PRO W7800, AMD Radeon RX 7900 XTX, AMD Radeon RX 7900 XT i AMD Radeon RX 7900 GRE. Jako, że jeszcze niedawno były to wyłącznie topowe modele Radeo Pro W7000 to widać, że rozwój oprogramowania idzie pełną parą (wsparcie dostał nawet Radeon RX 7600, ale jeszcze nie modele pośrednie). Dobrze, bo do funkcjonalności rozwiązań NVIDII wciąż jeszcze sporo brakuje.
Jeśli z kolei chcemy wykorzystać do obliczeń NPU wbudowane w procesory, to prawdopodobnie zadziała to na każdym modelu, który może się pochwalić taką funkcją (np. AMD Phoenix, czyli seria Ryzen 8000G) - musimy jedynie wybrać model językowy, który oferuje takie wsparcie.
Instalacja i konfiguracja LM Studio
Pierwszym krokiem jest oczywiście pobranie LM Studio i jego instalacja. Następnie musimy pobrać jeden (z wielu dostępnych) modeli LLM. Jeśli chodzi o sprzęt, do akceleracji AI wykorzystałem Radeona Pro W7900 (48 GB VRAM).
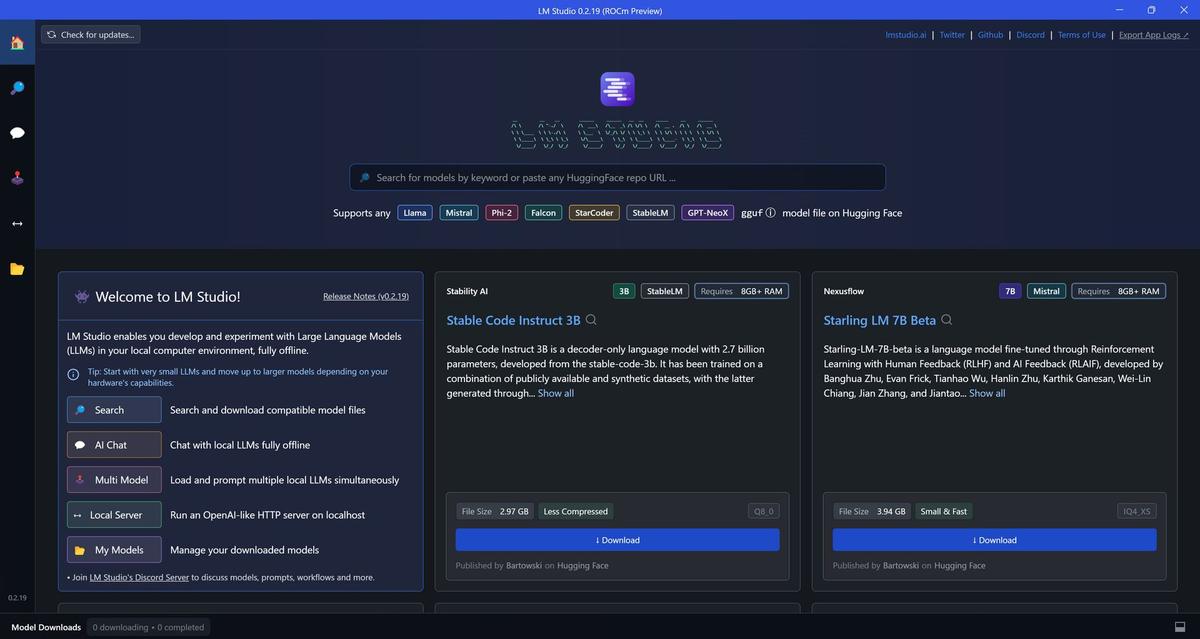
Na potrzeby tego poradnika wykorzystamy model Mistral. Wskazujemy konkretną wersję Mistrala, ale niech was to nie powstrzyma przed eksperymentowaniem - nie tylko z nowszymi wersjami, ale i z innymi modelami.
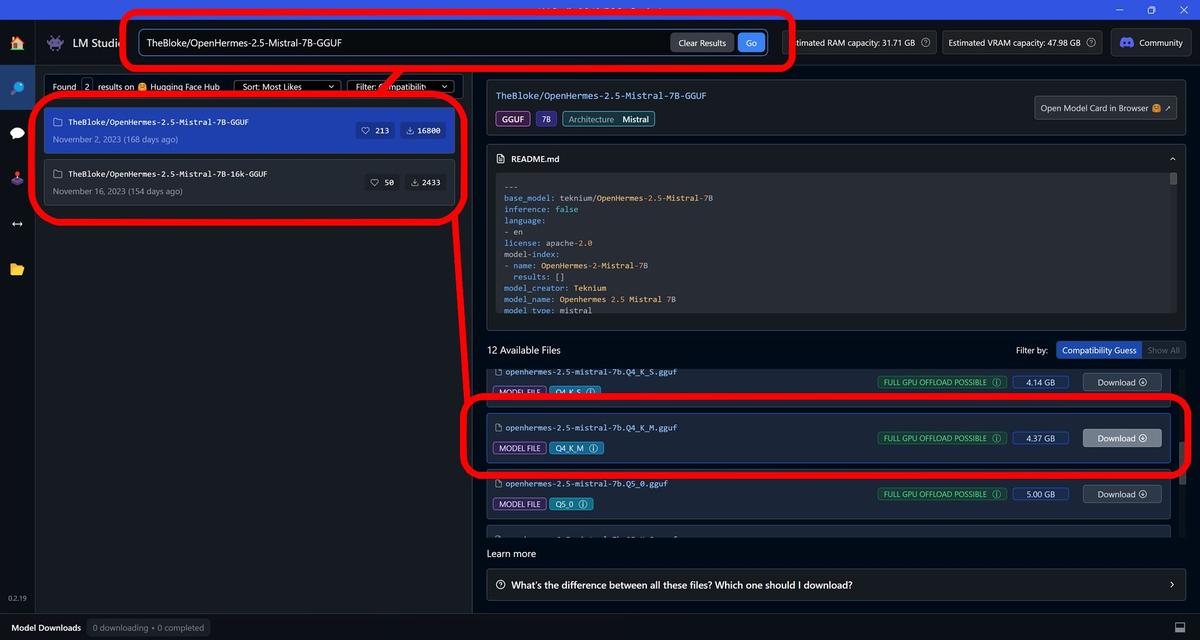
Wpisz w wyszukiwarce nazwę TheBloke/OpenHermes-2.5-Mistral-7B-GGUF i wybierz model. Po prawej stronie wybierz wersję Q4 K M, która powinna działać z większością procesorów Ryzen z NPU oraz oczywiście z obsługiwanymi kartami graficznymi.

Wybrany model należy następnie pobrać (co może chwilę potrwać) i wybrać go do załadowania, co dokonuje się w menu Chat.
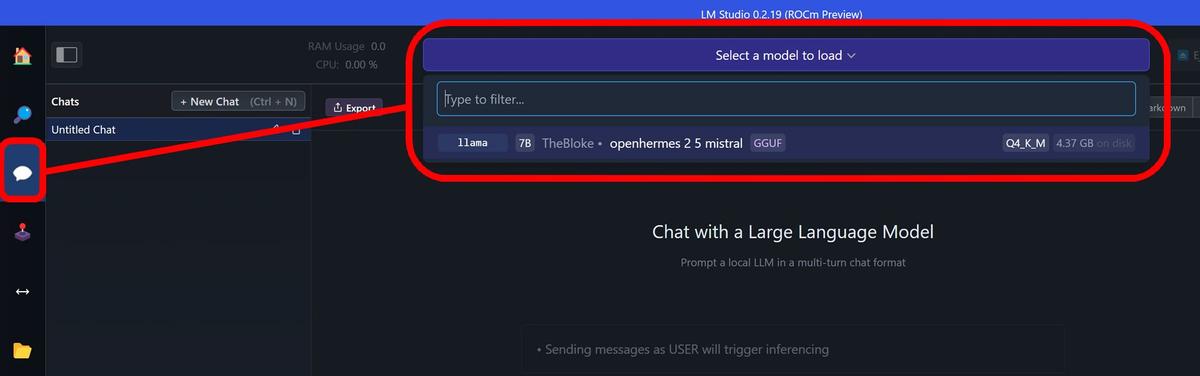
Jeśli chcesz uruchomić model na karcie graficznej Radeon, to przed jego trenowaniem upewnij się, że konfiguracja w pełni wykorzysta możliwości sprzętu. Wskaźnik GPU Offload powinien być ustawiony na maksimum, a wykryta karta graficzna (Detected GPU type) powinna korzystać z AMD ROCm.
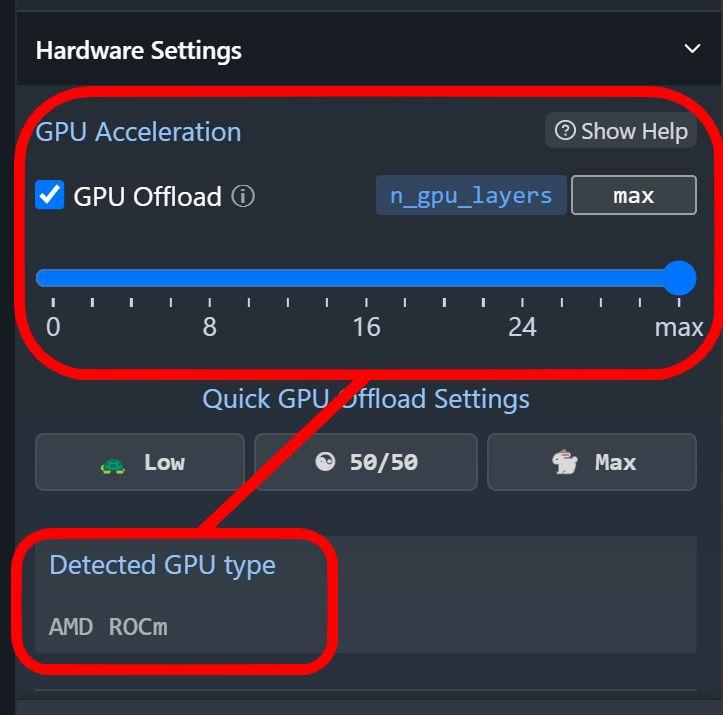
Jeśli po zmianie konfiguracji wyskoczy ci błąd, po prostu przeładuj model na nowo. Wszystko gotowe, teraz możesz konwersować z AI i lokalnie go trenować, bez wysyłania danych do internetu.
Zobacz inne artykuły o sztucznej inteligencji:
Twój lokalny bot AI na sprzęcie firmy NVIDIA (GeForce)
Jeśli do lokalnego trenowania LLM chcesz wykorzystać swoją kartę GeForce, to przypominamy, że służy do tego oprogramowanie NVIDIA Chat RTX. Wciąż jest w wersji demo, ale jest jak najbardziej funkcjonalne.