Po tym badaniu polski naukowiec, Łukasz Olejnik, został powszechnie cytowanym ekspertem ds. bezpieczeństwa
Dość rzadko się zdarza, aby osoba związana z nauką stała się z dnia na dzień powszechnie cytowanym przez media ekspertem w swojej dziedzinie. Tym przyjemniej, jeśli jest to naukowiec pochodzący z Polski.

Każdy kto śledził w ostatnich dniach technologiczne blogi i portale, zauważył doniesienia traktujące o technicznych możliwościach naruszenia prywatności użytkowników internetu poprzez API które pozwala przeglądarce m.in. odczytać stan baterii.
BBC, Wired, ArsTechnica, i wiele innych cytowały w nim badanie opublikowane przez Łukasza Olejnika - polskiego naukowca, dotąd pracującego we francuskim instytucie badawczym INRIA, a uprzednio w takich miejscach jak PCSS i CERN.
Łukasz zajmuje się dotyczącymi nas wszystkich zagadnieniami prywatności. Dla jego samego zainteresowanie mediów było dość niespodziewane, jednak starał się odpowiedzieć każdemu jak najlepiej, równocześnie propagując wiedzę o prywatności w sieci.
Mimo tego, że jest osobą, szczególnie w ostatnich dniach, dosłownie rozrywaną, zgodził się z nami porozmawiać.
Hubert Taler, Spider's Web: Przede wszystkim gratuluję niedawno zrobionego doktoratu we francuskim INRIA i zasłużonego rozgłosu jaki był twoim udziałem po publikacjach w mediach. Proszę powiedz kilka słów o sobie i o tym skąd się wziąłeś tam gdzie jesteś? Nad czym pracujesz, czym się zajmujesz?
Łukasz Olejnik: Serdecznie dziękuję za zainteresowanie moimi badaniami. Od zawsze interesowałem się nauką i technologiami. Obecnie mój profil zainteresowań to bezpieczeństwo informacji oraz prywatność (danych, użytkownika, etc) - z punktu widzenia technologii. Zarówno akademicko, jak i praktycznie, oraz teoretycznie. Mam także przeszłe prace, nazwijmy to "interdyscyplinarne", m.in. w kierunkach biotechnologii, czy kryptografii kwantowej.
Zajmuję się badaniami bezpieczeństwa i prywatności oraz R&D w tych kierunkach. Nieformalnie można stwierdzić, że jednym z moich celów jest sprawienie, by Internet był choćby odrobinę bardziej bezpiecznym i przyjaznym miejscem dla użytkownika.

W pewnym stopniu interesuję się i zajmuję też innymi aspektami bezpieczeństwa i prywatności, m.in. od strony wyzwań związanych z rozwojem technologii sekwencjonowania i genotypowania. Co jest coraz większym wyzwaniem (zarówno technicznym jak i legislacyjnym) w krajach, gdzie następuje szybki rozwój tego typu usług i technologii.
Mimo, że pojawiłeś się masowo w technologicznych blogach i telewizji, to temat ochrony prywatności fascynuje cię od dawna. Na twojej stronie wymienione są zaledwie niektóre z twoich opracowań i projektów. W szczególności ciekawi mnie What the Internet knows about you. Przybliżysz ten, lub kilka innych swoich innych projektów?
Były to projekty mające w dużej mierze popularyzować wiedzę i edukować ludzi na temat pewnej specyfiki przeglądarek internetowych. Otóż wchodząc na dowolną stronę w Internecie, mogła ona - w uproszczeniu - sprawdzić zawartość historii wcześniej przeglądanych stron, a konkretniej - czy pewne strony była odwiedzone. Ten problem długo czekał na rozwiązanie od strony przeglądarek. Nasz demonstrator pokazywał jak taka "detekcja" mogła wyglądać i że tego problemu nie można było już dłużej lekceważyć, ponieważ wydajność tej techniki wykrywania mogła nagle stać się bardzo duża. Problem ten doczekał się w końcu rozwiązania ze strony przeglądarek. I bardzo dobrze.
Innym ciekawym projektem z twojej strony jest Why Johnny can't browse in peace. Praca ta traktuje o czymś, co dotychczas było domeną książek z gatunku technothrillera - rozpoznawanie tożsamości po przyzwyczajeniach i nawykach związanych z korzystaniem z Internetu.
Tak, do pewnego stopnia preferencje przeglądanych stron mogą identyfikować użytkowników w sieci. Historia przeglądanych stron jest bardzo wrażliwym nośnikiem informacji i często zresztą były demonstrowane możliwości jej "przejęcia" przy wykorzystaniu wielu różnych technik. O wartości historii przeglądanych stron powstało też wiele prac, wiedzą też o tym choćby reklamodawcy w sieci. Wiedza taka pozwalaja na konstrukcję profili Internautów. Wynika to po części z faktu, że historia przeglądanych stron pozwala na wywnioskowanie informacji takich jak np. wiek, płeć, dochody, profil rasowy czy nawet charakter człowieka - nie wspominając nawet o bardziej konkretnych zainteresowaniach. Te informacje są często wykorzystywane do serwowania przekazu kierowanego, np. reklam internetowych.
Z innych projektów którymi się zajmowałem mogę wymienić też np. analizy systemów Real-Time Bidding pod względem bezpieczeństwa i prywatności.
Wyjaśnij proszę co to takiego?
Real-Time Bidding to najnowsza propozycja specjalistycznego kierowania przekazu sprofilowanego do użytkowników Internetu - system stosowany choćby na stronach internetowych, w sieciach społecznościowych, w reklamach w aplikacjach. Polega on na detekcji akcji użytkownika, przekazaniu dalej informacji o tych akcjach i prowadzeniu aukcji "o te akcje", w wyniku której do użytkownika trafia przekaz.
Czyli krótko mówiąc, reklama sprzedawana jest dopiero "po fakcie" wejścia na stronę?
Właściwie to w trakcie - aukcje zajmują zwykle około 100 milisekund. W przypadku odwiedzania stron internetowych może to wyglądać w sposób następujący: użytkownik wchodzi na stronę internetową. Za pośrednictwem skryptów na tej stronie operator sieci reklamowych (Ad Exchange) wykrywa tę wizytę. System ten przesyła do oferentów (ang. bidders) informacje o tej wizycie, zawierające pewne dane takie jak odwiedzana strona, identyfikator użytkownika, jego "wywnioskowane" zainteresowania, profil demograficzny i inne.
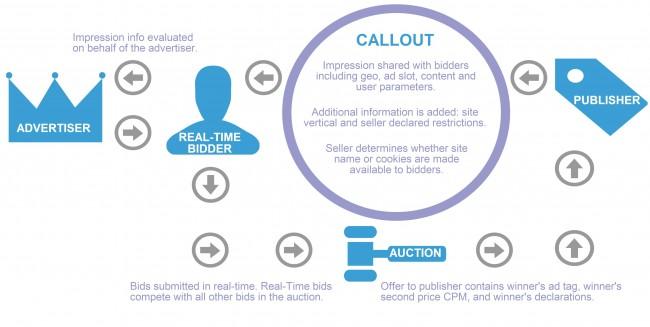
Oferenci biorący udział w aukcji wyceniają te informacje i zwracają do operatora sieci reklamowej swój przekaz (np. reklamę) i wycenę związaną z konkretnym użytkownikiem. Przekaz wygrywającego oferenta jest użytkownikowi wyświetlany.
Z systemami RTB wiążą się bardzo ciekawe problemy bezpieczeństwa, prywatności i transparentności. Moje prace dotyczyły systemów wymiany identyfikatorów między sieciami reklamowymi i oferentami za pomocą mechanizmu "cookie matching", przepływów informacyjnych, typowej "wyceny użytkowników" (i jej skalowania) i właśnie kwestii transparentności. Wyniki były prezentowane choćby w Network and Distributed System Security (NDSS) Symposium. Zyskały też pewne zainteresowanie w mediach - ale też i firmach technologicznych, gdzie w niektórych były prezentowane.
Mój artykuł na temat RTB ukazał się również na stronie Wszystko Co Najważniejsze.
Temat dzięki któremu prasa i telewizja nie daje ci ostatnio spokoju - nieomal z dnia na dzień stałeś się cytowanym przez wszystkich ekspertem - to informacje które można wyciągnąć "nie wprost" ze zużycia baterii w urządzeniu mobilnym. Pisałem kiedyś o podobnych badaniach z Uniwersytetu Stanforda w których próbowano na podstawie informacji o baterii uzyskać lokalizację użytkownika. Jak myślisz, jakie jeszcze czekają nas niespodzianki w tej dziedzinie?
O ile moje wcześniejsze badania także miewały oddźwięk w mediach, to muszę przyznać, że bardzo pozytywnie zaskoczyło mnie zainteresowanie akurat w tym momencie, tymi konkretnymi wynikami. Śledzę tego rodzaju tematy od strony technicznej od wielu lat i z doświadczenia mogę stwierdzić, że powinniśmy mieć otwarty umysł, ale też podchodzić do wszystkich takich doniesień na spokojnie. Rzeczywiście, jest wiele doniesień opisujących możliwości identyfikacji użytkowników na podstawie różnych źródeł, m.in. odwiedzanych stron w sieci, zainstalowanych aplikacji, odczytu z akcelerometru.
Są też problemy związane z samym odczytem zużycia energii, choćby w domach. Były tu m.in. demonstracje rekonstrukcji scen aktualnie oglądanych filmów na podstawie właśnie bieżącej analizy wykorzystywania energii elektrycznej.
Te i inne badania przede wszystkim pokazują, że techniczne budowanie systemów ze wsparciem dla prywatności jest mimo wszystko trudne. Trzeba zwracać uwagę na wiele aspektów. "Privacy is hard" - możnaby wręcz powiedzieć.
Niesamowite. Co nas może jeszcze czekać w tej dziedzinie, biorąc pod uwagę szybki rozwój Internet Of Things?
Możemy się spodziewać dalszych informacji dotyczących problemów związanych z urządzeniami mobilnymi, oczywiście z uwzględnieniem "Internetu Rzeczy" oraz potencjalnie dalszych problemów wynikających ze znacznego i nieustannego poszerzenia funkcji oferowanych przez przeglądarki. Te doniesienia są jednak czymś pozytywnym, bo zwykle wiążą się z badaniami i zidentyfikowanymi problemami. Pozwala to poszerzyć naszą wiedzę i świadomość w zakresie ryzyka bezpieczeństwa i prywatności.
Oby zaczęło nas to przybliżać do momentu, gdy wdrażane rozwiązania będą miały coraz mniej problemów i będą projektowane oraz utrzymywane w sposób przemyślany, a privacy stanie się by design (istnieje zresztą ruch tzw. "Privacy by Design" - przy czym ja oczywiście interesuję się tym od strony bardziej technicznej).
Czy oprócz zmuszenia producentów przeglądarek do utrudnienia przeglądania historii użytkownika, widzisz w technologiach internetowych inne zmiany na lepsze?
Przykładowo już od ostatniego czasu Internet (konkretniej: WWW) bardzo się zmienia. Coraz powszechniejsze jest wsparcie chociażby dla bezpiecznych połączeń z wykorzystaniem protokołu TLS. Przeglądarki internetowe podchodzą też do problematyki prywatności bardzo poważnie - na wielu poziomach, z uwzględnieniem "interfejsu - user experience".
Co więcej, coraz więcej firm również to robi i nie chodzi mi tu o przysłowiowe "we take privacy of our clients very seriously...", które regularnie pojawiają się w ogłoszeniach prasowych w przypadku jakiegoś rodzaju "wpadki" tej czy innej firmy, gdy okazywało się, że być może jednak "maybe not quite so...". Ale powtórzę, coraz więcej firm podchodzi do problemów bezpieczeństwa i prywatności użytkownika poważniej.
Czy możesz wyjaśnić nam na czym polegało Twoje badanie (to o baterii, które stało się tak popularne)? Co udało Ci się udowodnić?
Od pewnego czasu przeglądarki implementują "Battery API" - czyli mechanizm za pomocą którego strony internetowe mogą uzyskać pewne informacje o stanie baterii urządzenia użytkownika. Dokument opisujący ten mechanizm bardzo krótko traktuje o ewentualnych zagrożeniach dla bezpieczeństwa i prywatności, a wręcz zdaje się sugerować, że takie nie zachodzą. Mechanizm ten jest zatem dostępny bez potrzeby pytania użytkownika o zgodę, ani nawet informowania go o jego użyciu (co jest zresztą domeną również innych mechanizmów w przeglądarkach). Obecnie zaimplementowany jest on np. w przeglądarkach Firefox i Chrome.
My badaliśmy właśnie to zagadnienie. A zatem: czy są jakieś ewentualne problemy dla użytkownika, czy mogą wystąpić sytuacje, w których można ten mechanizm nadużyć, zidentyfikować sytuacje, kiedy mechanizm ten może np. przysłużyć się do "śledzenia", albo "rozróżniania" użytkowników w Internecie, oraz czy występują jakieś dodatkowe boczne kanały informacyjne (side-channels), lub czy dochodzi do wycieków pewnych informacji.

W tym miejscu muszę też przyznać, że bardzo ciekawe jest dla mnie jak wiele doniesień prasowych skupia się na W3C i tym standardzie, o którym faktycznie piszemy we wstępie do naszego raportu. Istotnie była to też jedna z motywacji naszej pracy. Osobiście uważam, że jest to też jeden z jej głównych punktów.
Zauważyłem też, że wielu ludzi (nawet bardzo biegłych w technologiach) zdaje się być zaskoczonych samym faktem istnienia tego mechanizmu w przeglądarkach internetowych.
Co więc doradziłbyś zwykłemu użytkownikowi Internetu na temat ochrony prywatności?
Mógłbym tu zacząć wymieniać: co zainstalować, jak skonfigurować, rozszerzyć, powyłączać.... Ale takich poradników (inna sprawa, że często mniej lub bardziej sensownie skonstruowanych) można wiele znaleźć w Internecie. Czy mogę zaoferować inne podejście?
Jednym aspektem są kwestie świadomości. Warto myśleć o tym, co robimy w sieci. Spróbować zastanowić się, jak to, co (i komu) ewentualnie udostępniamy może się w przyszłości rozwinąć, co często jest nawet trudne do przewidzenia...
Czy jeśli ktoś zapewnia, że nasze dane są anonimowe, to możemy spać spokojnie? Jak dowiedli naukowcy z MIT, wystarczają trzy "anonimowe" transakcje kartą, by przypisać je do konkretnej osoby. To jak to jest z tą anonimowością danych?
Toczy się właśnie wielka debata na temat tego, jakie dane są tzw. PII - "personally identifiable information" (dane osobowe, wrażliwe - legislacyjnie nie zawsze tożsame z "prywatnymi danymi"). Otóż z badań wynika, że ograniczanie się do uznawania za takie skończonego i określonego zbioru (np. dane jak "imię i nazwisko", "płeć", "wiek" i tak dalej...) jest niewłaściwe i w erze "Big Data" właściwie prawie wszystkie podejmowane akcje w sieci mogą być "personally identifiable". Czyli: mogą mieć potencjał identyfikacji, być unikalne.
Dobrze by było, żeby legislacje w końcu nadgoniły rozwój technologii w tych kontekstach.
Z tego mogłoby wynikać, że użytkownik właściwie niczego w sieci nie powinien robić, ale ważne jest by zachować tu zdrowy rozsądek. Choć istotnie badania z deanonimizacji wskazują na szereg problemów, spośród których wiele jest zaskakujących. Znacznym problemem staje się możliwość połączenia wielu źródeł informacji w "nową całość", która często udostępnia nowego rodzaju wiedzę, choćby tę deanonimizującą ludzi.
Twoja odpowiedź sugeruje że nic nie możemy z tym zrobić?
Nie jest aż tak źle. Z bardziej technicznych rad - należy być świadomym używanych technologii, znać ich ograniczenia, rozumieć pewną podstawową terminologię techniczną. Przykład: co naprawdę oznaczają choćby same określenia jak "share - udostępnij" lub "cloud - chmura"? Oczywiście często nie jest to łatwe, ponieważ niektóre z używanych rozwiązań nie są do końca transparentne w zakresie tego, co faktycznie robią. Trudno też oczekiwać od typowego użytkownika bycia ekspertem od technologii.
A co mogę jeszcze doradzić ściśle z zakresu technologii? Można choćby rozważyć szyfrowanie. Wszystkiego. Preferować strony udostępniające połączenie po protokole HTTPS, który zapewnia też kontrolę integralności danych - zabezpieczenie przed jej modyfikacją "w locie" - co jest właściwie bardzo wielką zaletą tego protokołu przy wchodzeniu na "zwyczajne" strony. Używanie smartfonów ze wsparciem dla pełnego szyfrowania. Rozważenie zachowania ostrożności przy używaniu tradycyjnych połączeń głosowych np. z wykorzystaniem konwencjonalnej telefonii (z którą związanych jest szereg problemów). W zamian za to można używać różnego rodzaju aplikacji do komunikacji. Choć niekoniecznie musimy wszędzie zakładać stylowe okulary modelu Censored Black:

I wracając do technologii - nie powinno być tak, że użytkownik w Internecie musi specjalnie myśleć o bezpieczeństwie i prywatności używanych technologii. Użytkownik nie powinien musieć zdawać sobie sprawy z wielu obecnie występujących zagrożeń i technikaliów. Nie jest prawidłową sytuacja, gdy wchodząc na pewną stronę internetową, coś "niepożądanego" może się użytkownikowi Internetu stać. To powinno po prostu działać. I to jest główne wyzwanie dla badaczy bezpieczeństwa i prywatności technologii, i Internetu.
Bardzo dziękuję za rozmowę!
*Grafika główna pochodzi z serwisu ShutterStock, fotografia okularów Censored Black od producenta.