Zobacz jaką drogę pokonuje skanowany dokument, nim dotrze na ekran twojego smartfona
Choć z całą pewnością możemy stwierdzić, że żyjemy w erze postępującej cyfryzacji, wiele dokumentów i książek nadal pozostaje dostępne jedynie w swojej analogowej formie. Chcąc wprowadzić je do komputerów, możemy je oczywiście zeskanować, lecz wtedy odbieramy sobie możliwość wygodnego przeszukiwania treści, czy też jej edycji. Tutaj z pomocą przychodzi mechanizm OCR, który w przypadku Google pozwala na transkrypcję aż 200 języków, w 25 standardach zapisu.

Optical Character Recognition, czyli rozpoznawanie znaków drukowanych, nie jest wbrew pozorom w żadnym wypadku wynalazkiem współczesnym. Swoją pierwszą formę przyjął już w roku 1914, kiedy to Emanuel Goldberg opracował maszynę, konwertującą tekst drukowany na sygnały telegraficzne. Dopracowany następnie w latach 20-tych i 30-stych XX wieku patent został wykupiony przez firmę IBM, i stosowany w medycynie (sprawdzano jego aplikacje dla osób niedowidzących), przemyśle, oraz biznesie.
Powszechny, komercyjny użytek OCR przeżywa jednak swój wielki rozkwit dopiero teraz, w dobie postępującej technologii mobilnej i smartfonów. Dotychczas stosunkowo rzadko mogliśmy skorzystać z programów do skanowania na naszych komputerach, które wykorzystywałyby tę technologię; nie były one także aż tak zaawansowane, jak te stosowane w aplikacjach mobilnych.
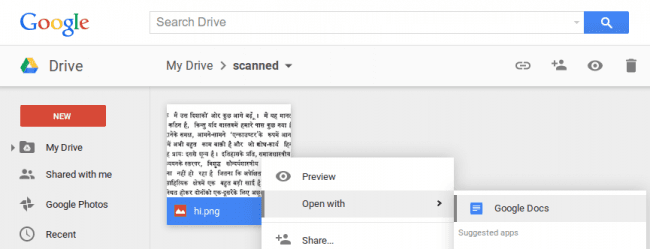
Pozostaje jednak faktem, że obecnie we wszystkich wiodących aplikacjach zastępujących skaner, znajdziemy bardzo zaawansowane algorytmy konwertujące wydruki do edytowalnego tekstu.
To co dla nas wygląda jak prosta czynność, wykonywana przez nasze smartfony w czasie kilku sekund, jest w istocie bardzo skomplikowanym technologicznie procesem, składającym się w gruncie rzeczy z trzech części - pre-skanu, rozpoznawania znaków oraz post-przetwarzania.
Podczas "pre-procesowania" algorytm w pierwszej kolejności wyrównuje zeskanowany obraz, pionizując wszystkie znaki graficzne. Im bardziej precyzyjnie to zrobi, tym większa szansa na poprawne odczytanie poszczególnych glifów.
Następnie program wygładza krawędzie, oraz "binaryzuje" obraz, oddzielając właściwą treść od jej tła, przetwarzając ją na dwutonową skalę szarości. Po tym etapie następuje usunięcie z obrazu wszystkich znaków, które nie są glifami, czyli np. linii pomocniczych, ramek etc.
Algorytm rozpoznaje także układ tekstu, dzieląc go na akapity, kolumny czy tabele. Jest to szczególnie istotny proces podczas transkrypcji wielokolumnowego dokumentu.
Gdy aplikacja rozpozna już typ zapisu, oraz odseparuje od siebie poszczególne znaki, przechodzi do procesu rozpoznawania zapisu. Początkowo wykorzystywano w tym celu dwie technologie - porównywania kolejnych glifów na poziomie pojedynczych pikseli, a w późniejszym czasie zamiast pikseli dzielono glify na większe elementy, co pozwalało na znacznie szybszą analizę i okazywało się przydatne w przypadku egzotycznych alfabetów.
Obecnie technologie te przenikają się nawzajem, do tego będąc nieustannie rozwijane, chociażby o takie możliwości jak adaptacyjne rozpoznawanie znaków, polegające w dużym skrócie na przewidywaniu kolejnych glifów na podstawie istniejących baz danych.
Oczywiście mówimy tu cały czas o mechanizmach OCR, gdyż obok tego istnieje osobna, choć ściśle powiązana dziedzina rozpoznawania pisma odręcznego, która rządzi się nieco innymi prawami.
Podczas post-procesowania zeskanowany i przetworzony obraz składany jest na powrót w jedną całość. Zaawansowane aplikacje bardzo często korzystają przy tym również z leksykonów, aby upewnić się co do logicznego zastosowania konkretnych słów, a także czasem ich kontekstowego rozpoznawania.
Właśnie dzięki rozpoznawaniu kontekstowemu aplikacje służące do skanowania obrazów mogą np. przetworzyć wizytówkę na nowy kontakt w telefonie, a kamery policyjne są w stanie odczytać numery rejestracyjne zarejestrowanych przez siebie samochodów.
OCR to nie tylko skaner dokumentów w telefonie
Rzecz jasna nasze smartfony w żadnym wypadku nie są i chyba nie powinny być priorytetem nadającym rozpędu badaniom nad technologią OCR. Od wielu lat algorytmy rozpoznawania drukowanego tekstu są regularnie dopracowywane i wykorzystywane głównie w celach archiwizowania analogowych danych, czego wartości nie da się przecenić.
Jeżeli ktoś ma co do tego jakiekolwiek wątpliwości, to wystarczy pomyśleć o całym środowisku naukowym, gdzie rozliczne publikacje, które nadal są aktualne i mają ogromną wartość dla studentów, dotychczas dostępne były jedynie w formie wydruków.
Teraz z pomocą OCR można tworzyć potężne bazy danych, takie jak np. Google Scholar (czy choćby prywatne archiwa Uniwersyteckie) gdzie studenci będą mogli wyszukiwać interesujące ich treści w skanowanych esejach, rozprawach naukowych, czy pracach doktorskich.
Pośród rozlicznych projektów cyfryzacji dziedzictwa kulturowego na wspomnienie zasługuje z pewnością Projekt Gutenberg, w ramach którego niedostępne, czy też bardzo rzadkie księgi mogą ukazać się w formie ebooka, który jest następnie powszechnie udostępniany.
Informacja o tym, iż algorytm OCR Google'a obsługuje już 200 języków w 25 typach zapisu jest o tyle interesująca, że otwiera to możliwości użycia tej technologii w zupełnie nowych rejonach. I nie mówimy tu tylko o funkcji skanera wbudowanej w Google Drive, lecz także o wspomnianych, bardziej istotnych zastosowaniach, które są teraz bardziej przystępne, niż kiedykolwiek.
To wszystko niby drobne rzeczy, lecz warto je mieć gdzieś z tyłu głowy za każdym razem, gdy wyciągniemy smartfona, by zeskanować dokument.
*Grafika główna pochodzi z serwisu Shutterstock