Pamiętasz, jak kiedyś wyglądał internet? Dzięki temu narzędziu możesz sobie przypomnieć
Sporo z Was zna pewnie stronę Wayback Machine. Zapisuje ona informacje jak strony internetowe wyglądały w przeszłości. Po wpisaniu adresu witryny www i wybraniu daty można do nich wrócić, nawet jeśli właściciele zdecydowali się na totalny redesing lub usunięcie witryny. Baza tego swoistego wehikułu czasu kilka tygodni temu doczekała się sporego uaktualnienia.

Znacie pewnie taki dowcip z brodą, że Chuck Norris zgrał internet na dyskietkę. Każdy szanujący się znawca internetu kręci na taki pomysł nosem, ale The Internet Archive, czyli twórcom Wayback Machine, najwidoczniej nikt nie powiedział, że to niemożliwe. Mozolnie starają się katalogować całą (dosłownie) światową sieć, zapisując u siebie kopie popularnych witryn.
Dzięki temu narzędziu można przyjrzeć się, jak te bardziej i mniej popularne portale wyglądały kilka miesięcy, a nawet lat temu. To olbrzymie archiwum zapisuje kopię stron głównych i wybranych podstron co większych serwisów. Spodziewać by się mogło, że archiwum będzie obejmować witryny anglojęzyczne, a tu niespodzianka - chętni mogą sprawdzić nawet, jak kilka lat temu wyglądał nasz Spider’s Web.

Oczywiście kopia znajdująca się w Wayback Machine nie jest pełnym odwzorowaniem 1 do 1. Zapomnieć można o działających wyszukiwarkach zwracających archiwalne treści, zaawansowanych skryptach, czy też możliwościach zakładania profili na nieistniejących forach. Wayback Machine daje jednak ogólny obraz tego, jak kiedyś wyglądał layout, i jakie treści pojawiały się na danej stronie. Można jednak często przeklikać się przez część witryny, czyli np. dotrzeć do pojedynczych postów na blogu. Strony zapisane w archiwum to nie tylko statyczne zrzuty ekranu w jpg.
Baza danych stworzona przez Wayback Machine jest ogromna, a ostatnio doczekała się nawet sporej aktualizacji. Na chwilę obecną można podróżować w czasie między końcem 2006, a siódmym grudnia 2012 roku. Zaindeksowane zostało na ten okres 240 miliardów (!) adresów URL, a rozmiar bazy danych to 5 petabajtów (czyli 5000 terabajtów). Co mnie osobiście zaskoczyło, to ilość osób korzystających z bazy: pół miliona dziennie. Nie wiedziałem, że to tak popularne narzędzie.
Sam na Wayback Machine trafiam średnio raz na rok, przeglądam kilka ulubionych stron, a później znów o niej zapominam. Traktuję to jako ciekawostkę, z której aż chce się korzystać - w końcu aby przejrzeć jej zasoby nie trzeba instalować żadnej aplikacji, ani uiszczać opłat. Wystarczy wpisać adres w wyszukiwarkę na stronie, a następnie wybrać konkretną datę z przejrzystego kalendarza. Można podejrzeć, jak kiedyś wyglądały popularne portale:

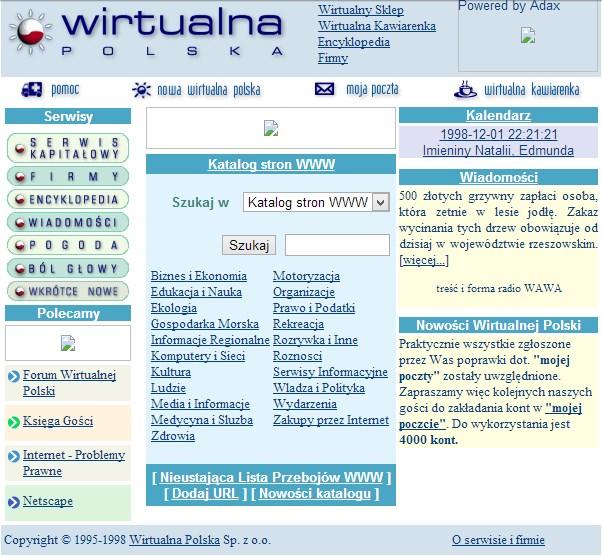


Przy Wayback Machine nie obyło się bez kontrowersji. W końcu jej twórcy zapisują kopię danych, więc nie sposób uniknąć sporów o prawa autorskie do treści i zdjęć, które przechowywane są na serwerach Internet Archive. Wayback Machine pozwala zgłaszać swoje zastrzeżenia, a także respektuje wstecznie informacje z pliku robots.txt, ukrywając na żądanie twórców strony z archiwum. Wayback Machine jest też czasem, z większym lub mniejszym powodzeniem, wykorzystywany w sądzie. Więcej na ten temat możecie przeczytać na Wikipedii, a może zachęcić Was fakt, że znalazła się tam wzmianka o Telewizji Polskiej.
Obecna wersja Wayback Machine może nie mieć dostępu do części starszych danych, ale administratorzy uspokajają, że już pracują nad poprawą narzędzia, aby wyświetlało wszystkie wyniki poprawnie. Zawsze przejściowo można skorzystać z poprzedniej wersji wyszukiwarki.
I chociaż wiele osób może stwierdzić, że to kawał porządnej, ale nikomu niepotrzebnej roboty, to ja się cieszę, że takie narzędzie istnieje.
źródło: blog.archive.org







































