Komputer od kilku miesięcy przegląda i analizuje obrazki w Internecie. Czego się nauczył?
NEIL to Never Ending Image Learner, program który jest uruchomiony od lipca 2013 roku w Carnegie Mellon University. Całymi dniami przegląda obrazki w Internecie próbując zbudować sobie wizualną bazę danych. Stara się zrozumieć cechy obiektów przedstawionych na obrazkach, relacje między nimi, oraz strukturę pozwalającą określić ogólną kategorię obiektu.

Dotychczasowe bazy wiedzy oparte są na danych tekstowych, które jednak nie odzwierciedlają w 100% ludzkiej wiedzy. Przykład: fraza "czarna owca" powtarza się w wynikach wyszukiwania w Google około 1,3 miliona razy, natomiast wyrażenie "biała owca" zaledwie 161 tys. razy. Program analizujący dane wyłączne tekstowe założyłby że czarne owce są o wiele częstsze - dopiero analiza komputerowych obrazów składowanych w Internecie przybliża nas do prawdziwych proporcji - zdjęć białych owiec jest o wiele więcej.
Projekt NEIL, który finansują wspólnie Google oraz Office of Naval Research (część amerykańskiego departamentu Marynarki, zajmującego się nauką i technologią), potrafi w tej chwili zidentyfikować:
- Kategorie obiektów - np. rower, samochód
- Relacje między obiektami - np. koło jest częścią samochodu
- Cechy obiektów - np. koło jest okrągłe
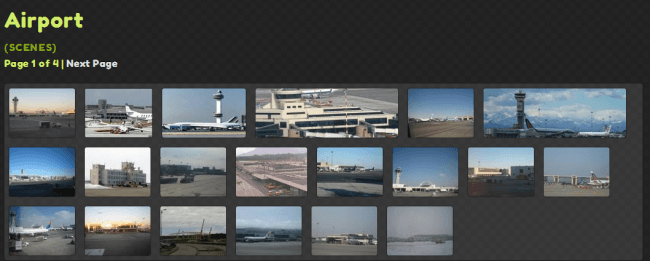
- Sceny - np. parking, łąka
Działając nieprzerwanie od kilku miesięcy, przeanalizował 5 milionów obrazów, samodzielnie oznaczył pół miliona z nich, i samodzielnie nauczył się trzech tysięcy (zweryfikowanych przez człowieka) sensownych relacji pomiędzy obiektami przedstawionymi na obrazach.
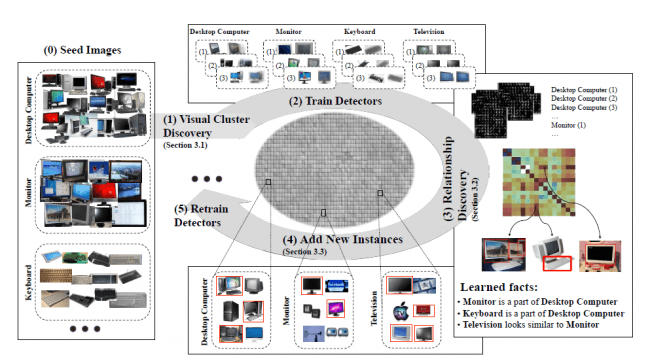
Twórcy NEIL-a udostępnili wyniki w formie przeszukiwalnej bazy danych.
Na stronie projektu (http://www.neil-kb.com/) można przeglądać część zbudowanej wizualnej bazy danych. Przeglądać można np. zidentyfikowane obiekty - po wybraniu wśród obiektów "adidas_ball" pokazuje się seria obrazów piłki adidasa, do tego tzw. clusters - czyli zestawy piłek o bliskich cechach, oraz zidentyfikowane cechy - w tym przypadku "Adidas_ball can be / can have Round_shape" (Piłka adidasa jest okrągła). Na stronie możemy przeglądać również sceny i cechy obiektów, jak również włączyć się do weryfikowania wyników (trenowanie NEIL-a).
Ludzka pomoc i weryfikacja wciąż jest potrzebna ze względu na ogromną liczbę wyjątków i cech obiektów zależnych od ludzkiej kultury. Twórcy NEIL-a byli zaskoczeni np. że zidentyfikował on Pink jako piosenkarkę a nie cechę (kolor), jak również tym że poszukiwania F-18 daje w wyniku nie tylko fotografie odrzutowców, ale i katamaranów klasy F-18...
Może nie wydaje się to mocno zaawansowane, ale biorąc pod uwagę, że jest to wynik pracy automatycznego procesu, daje ogromne nadzieje na inteligentniejsze wyszukiwanie obrazów w przyszłości, jak również zastosowanie praktyczne, np. wykrywanie obiektów danej kategorii na zdjęciach. Tutaj, biorąc pod uwagę również fundatorów projektu, możemy się domyślać również zastosowań militarnych (identyfikowania wrogich obiektów na obserwowanym lub fotografowanym z satelity obszarze). Jeśli pooglądamy sobie wyniki na zamieszczonej przez badaczy stronie, widzimy że obiekty rozpoznawane są w naprawdę różnej formie, z różnych perspektyw, czasami słabo widoczne. Zaczyna to powoli przypominać ten system identyfikacji obrazu, jaki każdy z nas nosi w postaci własnego mózgu.
Fotografia Wall with lot of photography pictures scattered in infinity pochodzi z serwisu ShutterStock.







































