Maciej Kuźniar: Autoskaler Oktawave poradzi sobie nawet z efektem Wykop, a ciebie to nie zrujnuje. Przykładowy test
Jest wiele powodów, dla których firmy coraz częściej wybierają publiczną chmurę obliczeniową. Szybkość, zwiększone bezpieczeństwo czy też oszczędności na inwestycjach. Ale to już wiemy. Dziś chciałbym Wam powiedzieć o kolejnym powodzie - możliwości zapewnienia sobie wysokiej dostępności swoich aplikacji sieciowych przy jednoczesnej możliwość płacenia tylko za te zasoby, które są w danym momencie potrzebne do utrzymania pożądanego poziomu szybkości i niezawodności.

Kiedyś musiałeś wybierać: dostępność albo przystępna cena
Jak jednak dobrać tę właściwą ilość zasobów? Obciążenia serwisów internetowych czy aplikacji webowych są dość nieprzewidywalne. Możemy się oczywiście przygotować na sezon świąteczny w sklepie internetowym, ale konia z rzędem temu, kto przewidzi najazd użytkowników Wykopu na naszą stronę.
Mniejsze serwisy, korzystające ze współdzielonego hostingu, VPS-ów czy nawet pojedynczych serwerów dedykowanych, w zasadzie przygotować się nie miały jak – w razie takiego oblężenia można było co najwyżej zamienić dynamiczną wersję strony głównej na statyczny HTML i czekać, aż ci wszyscy internauci sobie pójdą. Dlatego też serwisy, których operatorzy liczą się z większym ruchem, uruchamiają je zwykle na wielu serwerach, wykorzystując technikę równoważenia obciążenia (load balancingu) pomiędzy podłączonymi w klaster obliczeniowy maszynami.
Hosting tradycyjny zmusza więc najwyraźniej właściciela serwisu, któremu zależy na wysokiej dostępności w Internecie, do sięgnięcia jeśli nawet nie po maksymalną ilość zasobów infrastruktury, to przynajmniej wystarczająco dużą jej ilość, tak by sklep internetowy czy serwis informacyjny nie wyświetliły internaucie wesołej strony 503 w najmniej oczekiwanym momencie.
Takie zabezpieczenie oczywiście kosztuje. Firma hostingowa nie obniży nam przecież miesięcznego abonamentu za dzierżawę tylko dlatego, że wybrany do hostowania naszej aplikacji szybki serwer dedykowany, z czterema procesorami i szybkimi dyskami SSD, przez niemal cały miesiąc działał na pół gwizdka, zaledwie kilka razy odnotowując poważny skok obciążenia. Właściciel serwisu może mieć wrażenie, że przepłaca (i ma rację) – ale z drugiej strony co miałby zrobić, wybrać słabszą konfigurację i patrzeć jak za każdym razem, gdy wzrośnie zainteresowanie jego stroną, serwer będzie się mu topił?
Jak działa równoważenie obciążeń?
Dobrze byłoby więc mieć jakiś system, pozwalający poradzić sobie z takimi niespodziewanymi skokami. Zastanówmy się, jak wygląda problem, o którym tu mówimy. Przygotowany na różne okoliczności serwis internetowy to trzy warstwy: zwrócony na zewnątrz load balancer, przyjmujący żądania użytkowników i przekierowujący je do serwerów aplikacji, serwery aplikacji, na których uruchamiana jest logika oprogramowania, oraz serwery baz danych. Problem przeciążenia może dotyczyć każdej z tych warstw z osobna (i dlatego duże serwisy mają wiele load balancerów, nie mówiąc już o serwerach aplikacyjnych i bazodanowych), dla uproszczenia jednak skupmy się na warstwie logiki aplikacji.
Aplikacja działa na pewnej puli serwerów, z których każdy możliwy jest do zidentyfikowania po adresie IP. Teraz load balancer otrzymuje rozmaite żądania od użytkowników w ramach otwartych przez nich sesji i przekazuje je do jednego z serwerów aplikacyjnych w puli, wybierając go w ustalony sposób (np. losowo czy według najszybszej odpowiedzi). Im więcej żądań zostaje przekazanych do serwera aplikacyjnego, tym wolniej aplikacja będzie działać.
W sytuacji, gdy żądań robi się zbyt wiele, mamy dwie możliwości, aby utrzymać sensowną wydajność – albo zwiększymy liczbę serwerów w puli, albo dodamy do istniejących serwerów większą ilość pamięci i przyspieszymy działanie ich procesorów. Działania takie muszą być podejmowane automatycznie, przez mechanizm monitorujący rozmaite parametry działających w puli maszyn (np. obciążenie procesora, zużycie pamięci, ruch sieciowy, liczba wątków uruchomionych przez serwer WWW), i w zależności od ich zmian, modyfikujący zbiór zasobów infrastruktury, dodając lub ujmując określone elementy.
Bez względu na rodzaj podjętych działań, cel jest jeden – znaleźć równowagę pomiędzy oczekiwaną niezawodnością działania serwisu, a ilością wykorzystanych zasobów infrastruktury (pamiętając przy tym, że nic nie ma za darmo).
Nie ma automatycznego skalowania bez chmury
Gdy spróbujecie wyobrazić sobie działanie takiego systemu w tradycyjnym hostingu, sytuacja wygląda raczej komicznie – admini pospiesznie wciskający do szaf kolejne serwery, a do serwerów kolejne kostki RAM w momencie nagłego wzrostu popularności serwisu to chyba nie najlepszy pomysł. I tutaj właśnie najwyraźniej można zobaczyć przewagę chmury obliczeniowej.
Czym bowiem jest w chmura? Marketingowcy wymyślili wiele dziwnych definicji (włącznie z tak absurdalnymi jak ta, że chmura to po prostu Internet), ale dla nas w Oktawave chmura to zwirtualizowana pula zasobów infrastruktury, takich jak moc obliczeniowa, pamięć operacyjna, pamięć masowa czy interfejsy sieciowe. Jeśli serwis internetowy będzie działał w chmurze, to wszystkie te load balancery, serwery bazodanowe i aplikacyjne są z perspektywy zarządzania infrastrukturą po prostu kolejnymi maszynami wirtualnymi, z którymi możemy robić niemal wszystko, co zechcemy (i na co pozwoli nam hiperwizor i ich system operacyjny).
W takiej zwirtualizowanej puli zasobów, mechanizm monitorujący stan maszyn wirtualnych i w razie potrzeby modyfikujący ich liczbę czy parametry, nazywa się Autoskalerem. Wyróżnia się dwa rodzaje autoskalerów – horyzontalne, zmieniające liczbę maszyn wirtualnych w puli, oraz wertykalne, które zmieniają parametry maszyn wirtualnych. Ten drugi rodzaj, ze względu na ograniczenia systemów operacyjnych, pod których kontrolą maszyny wirtualne działają, jest znacznie trudniejszy w realizacji, o ile bowiem dodanie do działającej maszyny wirtualnej dodatkowego procesora czy RAM jest możliwe, to ich usunięcie jest bardzo problematyczne.
Dlatego większość dostawców chmur, na czele z Amazonem, oferuje swoim klientom jedynie autoskalery horyzontalne, które w zależności od liczby żądań przechodzących przez load balancer dodają i ujmują repliki zwirtualizowanych serwerów aplikacyjnych czy bazodanowych. Większość – ale nie my. Dzięki wykorzystaniu środowiska wirtualizacyjnego VMware możemy bez większych ograniczeń zmieniać typy serwerowych instancji, aby dopasować je do wymogów sytuacji.
Autoskaluj z Oktawave
Jak to wygląda z perspektywy użytkownika Oktawave? Po tej całej teorii czas na jakiś realny test Autoskalera. Oprogramowania do testów obciążeniowych serwerów i chmur jest bardzo dużo, często to skomplikowane frameworki, potrafiące symulować różne obciążenia robocze. Składają się one zwykle z testowej aplikacji uruchamianej na serwerze oraz generatora ruchu, symulującego aktywność internautów. Takie testy są przydatne przede wszystkim dla konstruktorów chmur, ale szeregowemu użytkownikowi za wiele nie powiedzą. Dlatego do naszego testu zdecydowaliśmy się wykorzystać popularnego WordPressa z zainstalowanymi kilkoma prostymi wtyczkami, darmową skórką i kilkoma stronami wypełnionymi przez tekst Lorem Ipsum.
Bloga uruchomiliśmy na instancji OCI typu Small, z systemem operacyjnym Debian 6. Do generowania obciążeń wykorzystaliśmy zaś narzędzia takie jak horde i Apache jMeter, uruchamiane z zewnętrznych serwerów (spoza sieci Oktawave).
Scenariusz testu przedstawia sytuację, w której bloger napisał interesujący tekst, który przez jego czytelników zostaje dodany do Wykopu. Tekst przebija się przez wykopalisko, trafia w końcu na główną stronę Wykopu, i nagle blog, odwiedzany dziennie przez 50-100 osób, zaczyna być odwiedzany zostaje przez 50-100 osób na minutę, a nawet jeszcze więcej. Jasne jest, że niewielka instancja, na której działa blog z czymś takim sobie nie poradzi. A czy poradzi sobie z tym sama chmura Oktawave?
Test Autoskalera w Oktawave
Zaczynamy skromnie. Wordpress, którego poddamy torturom, działa na jednej instancji serwerowej typu Small. Wertykalny Autoskaler skonfigurowaliśmy tak, by jako maksymalny typ instancji dopuszczał Large (próbowaliśmy też z Extreme i Colossus, ale Wordpress jest za słabą aplikacją, by przeciążyć te potężne instancje OCI).
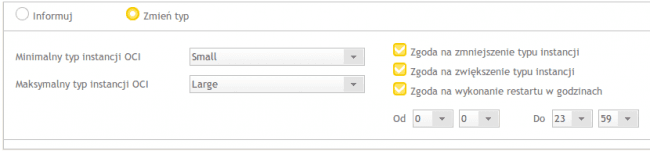
Autoskaler horyzontalny skonfigurowaliśmy tak, by w razie potrzeb uruchomił do trzech kontrolowanych przez loadbalancer instancji.
Zaczęło się niewinnie. Pojedyncze wejścia realnych użytkowników z wykorzystaniem przeglądarki. Nic się praktycznie nie dzieje.

Przygotowujemy obciążenie z pierwszego serwera. 30 symulowanych użytkowników zaczyna otwierać jedną ze stron bloga. Po 10 minutach nasza instancja OCI wygląda następująco.
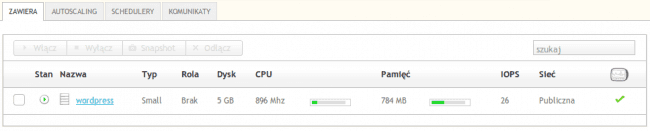
Jak widzicie, wraz ze wzrostem obciążenia przybyło mocy obliczeniowej i pamięci. Jednak nasza instancja tylko się marnuje. Dociążymy ją z drugiego serwera. 50 symulowanych użytkowników zaczyna wywoływać losowo wybrane strony z bloga, przeprowadzać zapytania do wyszukiwarki i robić inne miłe rzeczy, jak np. filtrowanie wpisów po kategoriach. Chyba trochę pomogło: po 20 minutach sprawdzamy stan naszej OCI z Wordpressem.
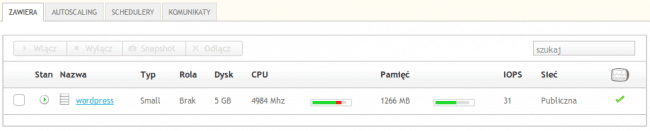
Maszyna jest przeciążona: wciąż zapewnia pełną dostępność, ale widać, że CPU nie daje już rady z tymi wszystkimi procesami Apache'a, obciążenie pamięci też znacząco wzrosło. Zwiększamy więc liczbę symulowanych użytkowników na pierwszym serwerze. Niech ich będzie 50 (wszyscy otwierają wybrany wpis blogowy).
Tego było już za dużo. Autoskaler zareagował i podniósł typ instancji.
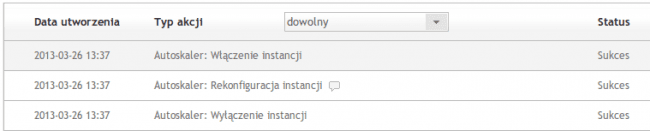
Large bez problemu radzi sobie z zadanym obciążeniem. Chwila przerwy w dostępności ze względu na ograniczenia jądra Linuksa – dodanie pamięci między klasami Small i Large wymaga restartu maszyny. Ale efekt jest.
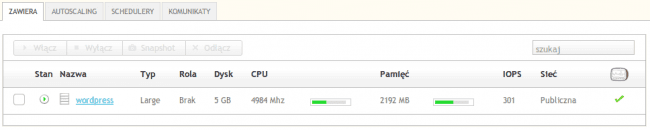
Próbujemy zwiększyć obciążenie, do akcji wchodzi trzeci serwer, od razu 100 użytkowników zaczyna otwierać jeden adres. Rezerwy wystarczyło, dostępność strony utrzymaliśmy, ale widać że i Large się męczy.

W takim razie niech się męczy jeszcze bardziej. Zwiększamy porządnie obciążenia na pierwszym i drugim serwerze: każdy symuluje teraz po 100 klikających po różnych wpisach bloga użytkowników. Autoskaler wertykalny się skończył, nie pozwalamy mu na przejście na typ Extreme... cała nadzieja w horyzontalnym Autoskalerze.
I faktycznie, coś się zaczęło dziać. W ramach kontenera pojawiła się druga instancja OCI, klon naszego Wordpressa. Load balancer zaczął przekierowywać ruch z przeciążonej maszyny.

Jednak i dwie instancje Large nie poradziły sobie z rozbuchanymi „simami”. Po 20 minutach Autoskaler powołał do życia trzecią.
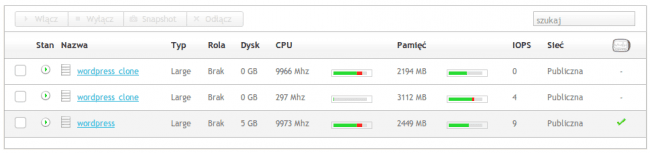
Zmęczyliśmy testem i siebie i instancję. Uśpiliśmy hordy użytkowników symulowane ze wszystkich serwerów. Autoskaler to zauważył, grzecznie wygaszając niepotrzebne instancje i skalując Wordpressa z powrotem do instancji Small.

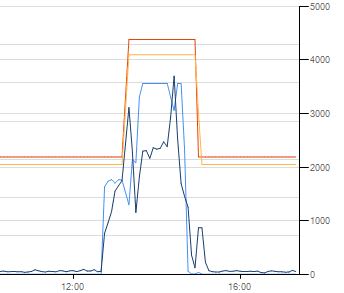
Zajrzeliśmy jeszcze do statystyk OCI. Przez cały czas autoskaler czuwał nad sytuacją, ani razu obciążenie maszyny wirtualnej nie przekroczyło niebezpiecznego poziomu:
Po najcięższym okresie testu z jednego z symulujących obciążenie serwerów otrzymaliśmy raport.
Availability: 99.83 %
Elapsed time: 3635.35 secs
Data transferred: 2690.35 MB
Response time: 0.02 secs
Transaction rate: 95.53 trans/sec
Throughput: 0.74 MB/sec
Concurrency: 2.02
Successful transactions: 347290
Failed transactions: 603
Longest transaction: 10.93
Shortest transaction: 0.00
A ile za to wszystko nasz bloger musiałby zapłacić Oktawave? Wygenerowaliśmy billing. Oto jego fragment:

Nie, to nie są ceny w bitcoinach. Za całą akcję z symulowanym Wykopem nasz bloger zapłaciłby 4 zł 37 groszy. Czy już widzicie, czym się różni serwer w chmurze od zwykłego VPS-a?
To nie jest dla innych. To jest dla Ciebie
Jak widzicie, z poziomu panelu administracyjnego Oktawave można się dobrze przygotować na takie nagłe wzrosty obciążenia. Definiując zawierający n instancji serwerowych kontener, możemy określić minimalną i maksymalną ich liczbę w kontenerze, oraz sposób zmieniania ich liczby – przez klonowanie czy dodawanie istniejących. Obsługującemu taki kontener load balancerowi możemy wybrać rozmaite algorytmy rozkładania obciążeń między instancjami, określić sposób utrzymania sesji (w zależności od potrzeb aplikacji), a nawet nakazać sprawdzanie dostępności usług.
Z kolei określając dopuszczalny zakres zmian typów instancji możemy wskazać typ minimalny i maksymalny, a także określić, w jakich godzinach może dojść do restartu instancji w celu zmniejszenia jej typu (zwirtualizowane systemy operacyjne mogą mieć problemy z ujęciem im RAM-u i procesorów, więc przy takich operacjach konieczne jest ponowne uruchomienie serwera). Możemy też za pomocą schedulera określić godziny, w których autoskalowanie będzie możliwe, jak również wymusić skalowanie instancji do danego typu w określonych terminach.
Pewne kwestie jednak „skalibrowaliśmy” sami, na sztywno, podczas prac nad optymalizacją działania naszego Autoskalera. Aktywuje się on po przekroczeniu pewnych progowych wartości obciążenia procesora i pamięci w danej instancji – jeśli nawet jeden z tych parametrów przekroczy 90%, system powiększa typ instancji (do maksymalnego dopuszczonego), jeśli oba te parametry zejdą poniżej 50%, system zmniejsza typ instancji. Podobnie też w Autoskalerze horyzontalnym – gdy ponad 50% instancji wymaga zwiększenia zasobów, dodajemy w kontenerze jedną instancję, gdy zaś ponad 50% instancji w kontenerze można zmniejszyć, odejmowana jest jedna instancja.
Gdy obciążenie się zwiększa, najpierw uruchamiany jest Autoskaler wertykalny, by podwyższyć typ instancji, gdy obciążenie maleje, pierwszeństwo ma Autoskaler horyzontalny, czyli zmniejszana jest liczba uruchomionych instancji.
Niestety, ze względów technicznych Autoskaler nie działa w czasie rzeczywistym. Wszystkie operacje odbywają się z opóźnieniem 15-20 minut – tyle wynosi okienko czasowe, dla którego analizowane jest średnie obciążenie instancji OCI. Dlatego też nagłe, krótkie skoki nie spowodują zmian w konfiguracji maszyn wirtualnych. Na szczęście samo klonowanie, dodawanie i usuwanie instancji jest procesem bardzo szybkim, zajmuje od kilku do kilkudziesięciu sekund, więc reakcja na przeciążenia po ich wykryciu następuje praktycznie od razu.
A jak się to przekłada na oszczędności? Cóż, użytkownik Oktawave nie płaci za „puste przebiegi” serwera. Gdy obciążenie jest małe, jego serwis działa na pojedynczej instancji, to i koszt hostingu jest niski. Gdy obciążenie nagle skacze, a Autoskaler powiększa typ instancji i dodaje kolejne wirtualne maszyny do kontenera, to koszt hostingu jest… też niski – pobieramy w końcu opłaty tylko za godziny, w których te dodatkowe wirtualne maszyny faktycznie działały, gdy bowiem przestają być potrzebne, Autoskaler zadba o to, by je usunięto.
A że koszt zmiany typu istniejącej instancji jest mniejszy, niż koszt uruchomienia nowej instancji, to możemy klientom zaoferować całościowo niższe ceny hostowania ich serwisów, niż oferuje to dysponująca jedynie horyzontalnym Autoskalerem konkurencja.
PS Zachęcamy Czytelników Spider’s Web do zadawania pytań i pogłębiania wiedzy. Jesteśmy tutaj, by pomóc Wam w adopcji optymalnych i oszczędnych rozwiązań dla Waszych projektów. Przypominamy też, że teraz każdy może przetestować Oktawave za darmo, korzystając z naszej promocji: http://www.oktawave.com/pl/promocje/25-na-start.html.

Maciej Kuźniar - dyrektor projektu Oktawave. Pasjonat technologii związanych z przetwarzaniem i przechowywaniem danych, posiadający 10 lat doświadczenia w pracy dla klientów klasy enterprise (banki, telekomy, fmcg). Autor koncepcji technologicznie wspierających rozwój startupów oraz rozwiązań architektonicznych gwarantujących wysokie HA i SLA dla systemów IT.







































